
Building Ontology with LLMs: Five Methods Compared
Covering 9 papers from 2025–2026 · A complete decision guide from exploration to production

Here’s a problem most AI engineers hit eventually.
You build a RAG system, stuff your documents in, and start answering questions. Works fine until someone asks the same thing three times and gets three different answers. Today the LLM says Supplier A’s rating is 85. Tomorrow it says 92. The day after, 78. The LLM isn’t lying — it just doesn’t know the relationship between “supplier,” “rating,” and “date.” It guesses every time.
The fix is an ontology — a structured knowledge map that doesn’t just store data, but defines relationships and rules between entities. With one, your AI goes from guessing to querying. And it can chain-reason: material shortage → affected production lines → affected customer orders.
Four Contradictions in Traditional Ontology Building
Before LLMs, building an ontology meant: knowledge engineers and domain experts sitting together for months, sketching on whiteboards, hand-writing definitions in OWL (Web Ontology Language, the W3C standard) and SHACL (Shapes Constraint Language, for data validation). This approach has four fundamental contradictions:
The speed contradiction: Manual modeling is too slow for business change. By the time the ontology is finished, the business has already shifted.
The talent contradiction: People who understand both OWL/SHACL and the specific business domain are extremely rare. The two skill sets almost never overlap in one person.
The maintenance contradiction: Once built, nobody maintains it. The ontology gradually becomes a “dead model,” unable to evolve with the business.
The scale contradiction: Manual approaches can’t handle large document volumes. The method collapses as document scale increases.
LLMs happen to have three capabilities that address exactly these needs: extracting structured information from unstructured text, understanding domain semantics, and generating standard formats like JSON and OWL. But using LLMs naively for ontology construction runs into four hard problems:
Problem 1: You don’t know how many concept types exist — 10 or 1,000?
Problem 2: LLMs hallucinate, inventing concepts that aren’t in the source text
Problem 3: Granularity is hard to calibrate — “has a relationship” is too vague, “is to the left of” is too specific
Problem 4: No ground truth to validate against, so you don’t know if the result is good
Between 2025 and 2026, five distinct methods emerged from the research literature to address these four problems.
Method A: Pipeline Decomposition
Hallucination risk: Low
Engineering complexity: High
Key papers: Salovsky 2026 · IRT SystemX 2025 · Wikontic 2025
Break the big task into controlled steps, using the best tool for each. Standard pipeline:
Document input → ① Entity extraction (NER) → ② Relation extraction → ③ Deduplication
→ ④ Dual validation → ⑤ Write to graphEach step spelled out:
identify named entities from documents;
determine relationships between entities;
merge “Supplier A” and “SUPPLIER-A” into the same entity;
structural compliance + logical consistency dual check;
write to graph database.
The Validation Loop Is the Core Innovation
The critical feature of this school is dual validation. Every new fact must pass two layers of checks:
SHACL (Shapes Constraint Language, W3C standard validation language) structural validation: Is the data schema-compliant? For example, “an order must have a customer ID that is an integer”
OWL Reasoner logical validation: Are there contradictions? For example, a concept cannot simultaneously be a parent class and a child class of another concept
Pass validation → write to the trusted graph. Fail → log it, don’t contaminate the knowledge base.
Salovsky (2026) adds MCP protocol orchestration to coordinate LLM, RDF/OWL graph, vector RAG, and external APIs. The LLM serves only as an “interpretation, generation, and orchestration layer” — the actual world model lives in the RDF/OWL graph. Validated with Tower of Hanoi tests: 5-disc success rate improved from 33.3% to 45.5%.
Industrial Case: IRT SystemX × EDF (2025)
Partners included IRT SystemX, EDF (France’s national electricity utility), Airbus, and RTE (France’s electricity grid operator). Semi-automated ontology construction from French technical documentation. Their 7-layer pipeline:
Text preprocessing (French POS tagging, domain-specific tokenization)
NER (RTE uses regex; EDF uses fine-tuned CamemBERT)
Relation extraction (RTE uses RelationPrompt; EDF uses fine-tuned LUKE)
Metadata enrichment (DBpedia/Wikidata SPARQL extension)
Version lifecycle management (Populated → Enriched → Evaluated → In-use → Archived)
Evaluation (NER-evaluate + OOPS! + FAIR Explore)
KG generation and visualization (Flask + VueJS + SPARQL)
FAIR data quality score improved from 22.5% (V1.1) to 36.11% (V1.3). Note: this project actually uses traditional deep learning models — CamemBERT, LUKE — with plans to integrate Mistral/Gemma in future iterations.
Lightweight Case: Wikontic (2025)
Uses Wikidata as a skeleton constraint for LLM output. Key numbers:
Only <1,000 output tokens — one-twentieth the cost of GraphRAG
MuSiQue benchmark: 96% of triples contain correct answer entities
HotpotQA: 76.0 F1 (using triples only, no text context needed)
MINE-1 benchmark: 86% SOTA information retention rate
Strengths: Every step is controllable and swappable; lowest hallucination risk; supports versioning and continuous updates.
Weaknesses: Errors in earlier steps propagate forward; high engineering complexity and setup cost; multi-step LLM calls consume more tokens overall.
Best for: Production systems where quality is non-negotiable.
Method B: Clustering-Driven
Hallucination risk: Low
Engineering complexity: Medium
Key paper: LLM4Onto 2025
Don’t define categories upfront — let the data decide. Core pipeline:
Documents → Extract nouns (SpaCy) → Vectorize (BERT) → AP clustering (auto-group)
→ LLM names each cluster → Multi-round merging → OntologyWhy AP Clustering Instead of K-means
K-means requires you to specify the number of clusters in advance. When you’re building an ontology for an unfamiliar domain, you don’t know that number. Affinity Propagation (AP) determines its own cluster count based on data similarity. If AP over-segments (splitting “apple,” “banana,” and “pear” into three separate clusters), the LLM merges similar clusters back through multi-round dialogue into “fruit.”
The HT-R-O Three-Stage Relation Extraction Pipeline
Relation extraction is the hardest part of ontology construction. LLM4Onto compared three paradigms:

The three HT-R-O steps with concrete examples:
Step 1 (Instance-level extraction)
Input: "HoneyMyte group uses ToneShell backdoor"
Output: (HoneyMyte, use, ToneShell backdoor)Step 2 (Ontology-level abstraction)
Output: (APT group, use, malware)Step 3 (Relation standardization)
"use" / "employ" / "leverage" → unified as "use"Benchmark Results
MultiWOZ: Literal F1 of 49.5% (baseline TeQoDO scores only 2.8%)
Cybersecurity domain: Discovered 483 entity types + 72 relation types (traditional NER models identify only 13–40)
ArXiv: Graph F1 of 68.68%
Strengths: Truly data-driven with no manual annotation needed; no prior knowledge of category types required; small-task decomposition keeps hallucination risk low.
Weaknesses: Clustering quality directly determines final output quality; no built-in online validation; open-domain scenarios may over-fragment into too-fine granularity.
Best for: Exploring new domains where you don’t know what concept types exist.
Method C: Two-Phase Generation
Hallucination risk: Medium
Engineering complexity: Medium
Key papers: OntoEKG 2026 · NeOn-GPT 2024
Phase 1 (Extraction Module): have the LLM identify candidate classes and attributes from unstructured documents. Phase 2 (Entailment Module): organize that flat list into a logical hierarchy and serialize to RDF. The two phases are separate — the intermediate output is human-reviewable and adjustable.
Unstructured docs → Phase 1 (Extraction Module) → Phase 2 (Entailment Module) → RDF serialization Identify core classes + attrs Organize into logical hierarchyOntoEKG (ICSC 2026): Achieved fuzzy-match F1 of 0.724 in the Data domain. Limitation: when concept hierarchies get complex, the model tends to flatten rather than properly nest. Hierarchy reasoning is still the weak point.
NeOn-GPT (Fathallah et al., 2024): Follows the NeOn ontology engineering methodology, using LLMs to replace most of the manual work. Workflow: requirements writing → OWL encoding → evaluation → documentation generation. Integrates GPT-3.5, LLaMA, and PaLM as interchangeable model backends.
Strengths: Clear intermediate artifacts that can be reviewed; fast construction of an initial ontology draft; medium engineering complexity, easy to get started.
Weaknesses: Two-stage errors compound; hierarchy reasoning quality depends on LLM capability; no built-in validation mechanism.
Best for: Fast first drafts for direction validation; cases where you need visibility into intermediate state.
Method D: Schema-Guided Extraction
Hallucination risk: Low | Engineering complexity: Medium | Key papers: OntoKG 2026 · Wikontic 2025
Start with a framework, extract within it. Rather than letting the LLM freely invent “what relationship is this?”, constrain it to choose from a defined list: “Is this relationship ‘belongs to,’ ‘located in,’ or ‘causes’?” The option space is bounded, so the hallucination space shrinks accordingly.
Existing schema (Wikidata etc.) → Define type and relation lists → LLM extracts within schema → Schema validation → Compliant outputSchema-Free vs. Schema-Based

The 2025 Bian survey concludes: these two are complementary, not competing. The ideal system = Schema-Free discovers new concepts first → Schema-Based formalizes them into standard structure.
Large-Scale Case: OntoKG (2026)
Organized Wikidata’s 346 million entities into 94 modules across 8 categories. The core mechanism — intrinsic-relational routing:
Each property → Intrinsic attribute (color, size) → node attribute module
Each property → Relational attribute (located in, part of) → edge module
LLM + human review results: 93.3% category coverage, 98.0% module assignment accuracy, encompassing 34 million nodes, 61.2 million edges, and 38 relation types.
Strengths: Output is naturally schema-compliant with small hallucination space; low engineering effort when a good schema exists; fits regulated industry standards.
Weaknesses: Constrained by the coverage of the existing schema; weak at discovering genuinely new concepts; requires a suitable schema to exist upfront.
Best for: Domains with existing industry standards or data specifications (healthcare, legal, energy, etc.).
Method E: End-to-End Prompting
Hallucination risk: High | Engineering complexity: Low | Key benchmark: LLMs4OL Challenge 2025
One prompt, full output. Fast to implement:
You are a {domain} ontology expert.
Extract ontology classes and their relationships from the following text.
Only extract what is explicitly stated. Do not add inferred content.
Output format: JSON.
{"classes": [{"name": "...", "definition": "..."}],
"relationships": [{"source": "...", "target": "...", "type": "..."}]}
Rules: 1. Only extract explicit content 2. Use standardized names 3. Output "None" if ambiguous
Text: {input_text}
Four key findings from the LLMs4OL 2025 challenge:
No universal winner: No single model performs best across all subtasks
Small models + good prompts ≈ large models: Well-crafted prompts sometimes let small models match large model performance
Extreme prompt sensitivity: Minor wording changes produce significantly different ontology structures from the same model
Fastest results: A first draft in 30 minutes, suitable for quick direction validation
Strengths: Simplest to implement, zero engineering setup; results in 30 minutes.
Weaknesses: Highest hallucination risk; unstable output quality; prompt sensitivity seriously affects output.
Best for: Quick proof-of-concept validation. Not suitable for production.
Five Methods Side-by-Side
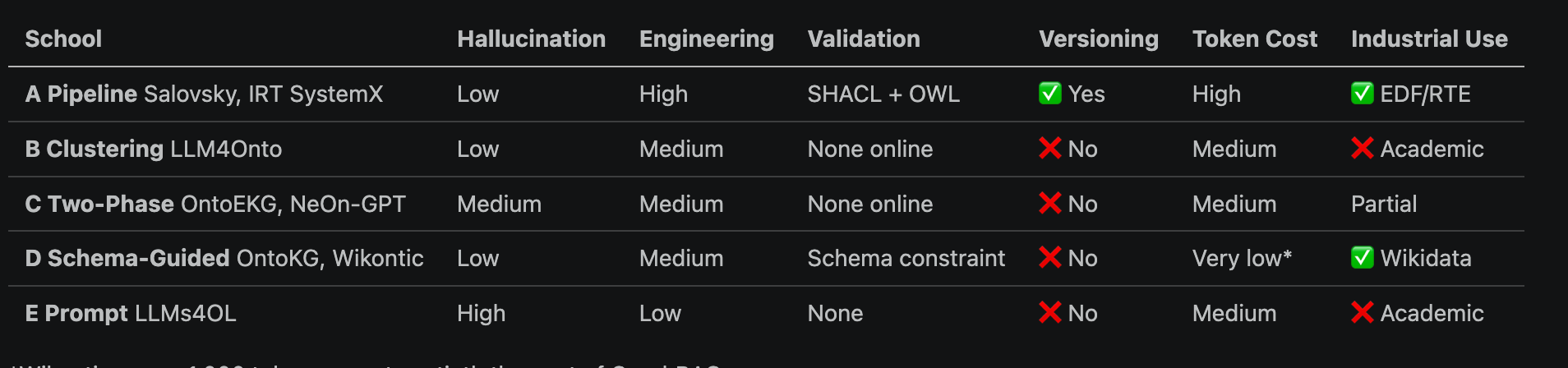
*Wikontic uses <1,000 tokens, one-twentieth the cost of GraphRAG
The Decision Framework

Five Engineering Lessons From the Literature
Lesson 01: NER is where most errors originate
Salovsky (2026) explicitly flags this: “most future errors originate in the NER phase.” Wrong entity types, alias confusion, and incomplete type coverage in the extraction phase propagate through every downstream step. IRT SystemX’s experience confirms this: RTE used regex while EDF fine-tuned CamemBERT — the right choice depends on how much labeled data you have. Invest here before optimizing anything else.
Lesson 02: Relation extraction is much harder than entity discovery
Finding “what things exist” is relatively straightforward. Understanding “what relationships exist between those things” is the real challenge. LLM4Onto specifically designed the 3-stage HT-R-O pipeline to handle this. IRT SystemX found certain relation types (like “ending time”) were far more ambiguous than others. OntoEKG showed clear limitations in hierarchical reasoning. Recommendation: extract coarse-grained relations first, then use LLM to refine and standardize.
Lesson 03: Validation is the line between toy and production
Without validation, you’re letting the LLM write whatever it wants into your knowledge base. LLM4Onto has no online validation mechanism — that’s one reason it remains a research prototype. Minimum viable: SHACL structural validation. If you can, add OWL Reasoner for logical consistency checks.
Lesson 04: Prompt wording affects output structure
García-Fernández et al. (2025) found that minor prompt wording changes from the same LLM produced significantly different ontology structures. Use structured templates with explicit rules and examples, not free-form natural language descriptions. Validate output format programmatically — don’t trust that the model produces consistent JSON structure.
Lesson 05: More tokens doesn’t mean better quality
Wikontic built an effective knowledge graph with under 1,000 output tokens — one-twentieth of GraphRAG’s cost. High token consumption doesn’t necessarily produce higher accuracy. The key is not data volume, but data quality and the reasonableness of constraints.
Where This Field Is Heading
Trend 1: Schema-Free and Schema-Based are converging
Let LLMs freely explore and discover new concepts first, then automatically integrate new concepts into standard frameworks — the “from disorder to order” loop is becoming the dominant design pattern. The Bian survey (2025) calls this the ideal architecture.
Trend 2: Ontologies are becoming the memory layer for AI agents
Ontologies aren’t just static knowledge bases for querying. They’re becoming the “world model” for AI agents — the agent uses it to understand current state, plan next actions, and record execution results. This direction becomes increasingly important as agent frameworks mature rapidly.
Trend 3: Extension from text to multimodal sources
Extracting ontologies not just from text, but from charts, images, and sensor data. This direction is just starting, and represents the next significant growth area in the field.
Trend 4: Standardized evaluation is being established
The LLMs4OL challenge, the UPM survey, and similar efforts are driving unified evaluation standards — allowing different methods to be compared on the same scale. Without standardized evaluation, there’s no real progress comparison between approaches.
Tool Building
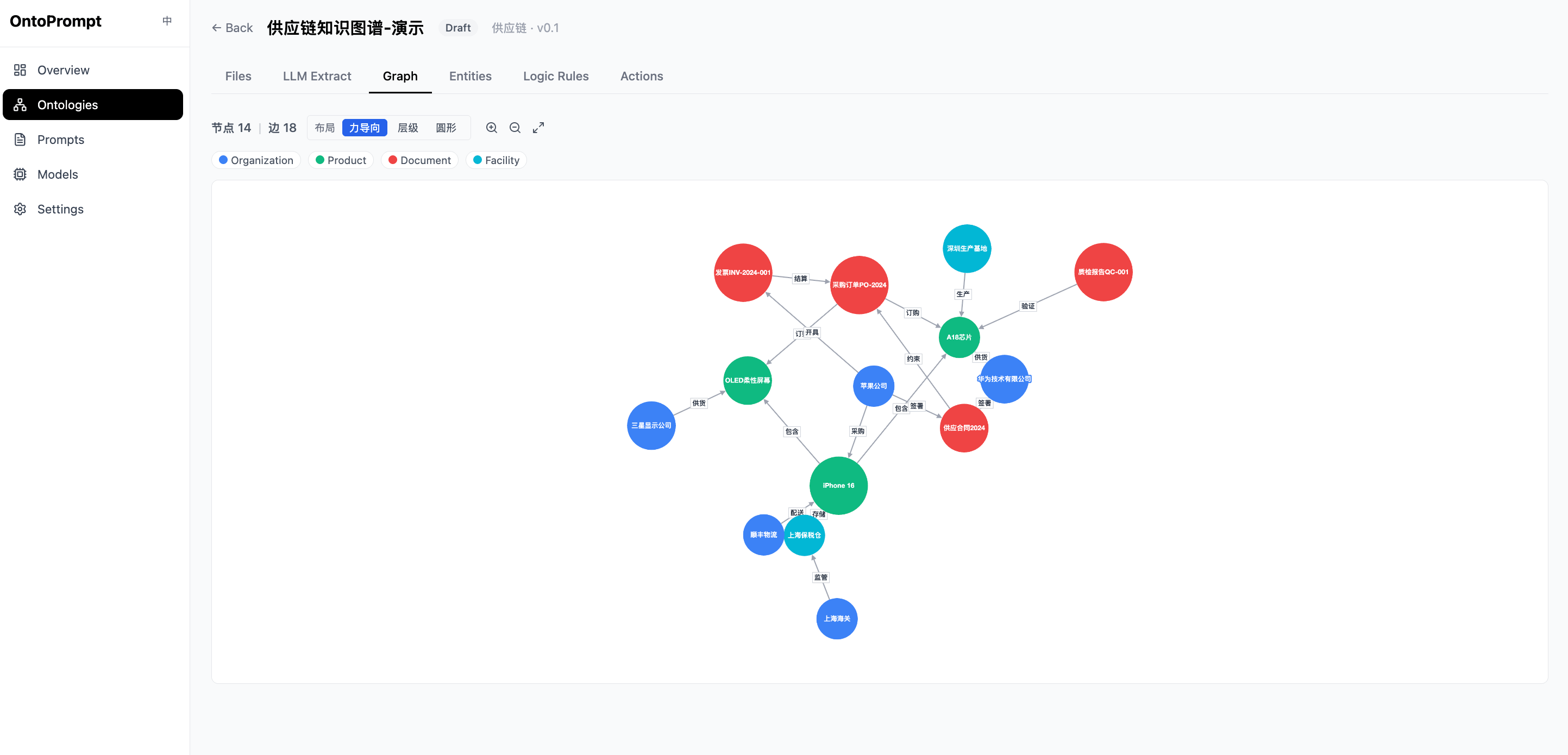
In order to understand ontology and how LLM drives ontology construction, I have built a tool called OntoPrompt in my github:
https://github.com/jingw2/nano-ontoprompt
This OntoPrompt is a nano platform using Prompt + Rule based + LLM methods to construct ontologies in different domains.
Welcome to try it.
Terminology Reference

The question has shifted from “can LLMs build ontologies?” to “which approach fits your constraints?” Your task scope, engineering resources, and quality requirements determine the answer — not which paper was published most recently.
Five schools, five tradeoffs. None of them is universally superior. The right one depends on where you are: a 30-minute prototype or a production system that can’t be wrong.
Zero Future covers applied AI engineering weekly. Subscribe to stay current.