
DeepSeek V4: The Engineering Breakthrough Behind China’s Most Credible AI Model
What happens when a lab stops chasing headlines and just ships real infrastructure

The closing line of DeepSeek’s V4 announcement quotes a 3rd-century BCE Confucian text:
“Not seduced by praise, not deterred by slander — walk the true path, correct yourself, unmoved by all.”
In an industry where every lab is racing to drop a benchmark screenshot before noon, this is a strange thing to publish. DeepSeek just shipped a technical report, acknowledged its own limitations in the same breath, and moved on.
That posture is itself a data point worth taking seriously.
If you are a visual learner, you are able to watch my youtube video (Chinese):
What You’re Actually Dealing With
V4 ships as two distinct models, not marketing tiers of the same thing:
V4-Pro: 1.6 trillion parameters, 49B activated, 61 layers deep
V4-Flash: 284B parameters, 13B activated — the economical option
Both support a 1 million token context window. That’s the entirety of The Three-Body Problem trilogy fed in, with arbitrary detail retrieval.
But the headline number isn’t the scale — it’s the efficiency delta. Processing a million-token context compared to the previous generation:
V4-Pro: 27% of the compute, 10% of the VRAM
V4-Flash: 10% of the compute, 7% of the VRAM
This isn’t incremental optimization. It’s an architectural rethink.
Three Core Technologies, Explained Without Jargon
Hybrid Attention (CSA + HCA): Skim First, Then Read
The naive approach to long-context processing: compute relationships between every token and every other token. Compute explodes quadratically.
V4’s approach is hierarchical compression:
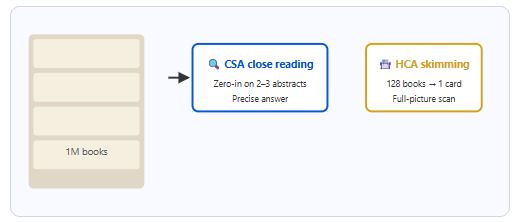
CSA (Compressed Sparse Attention): merges every 4 tokens into a summary unit, enables precision retrieval of relevant segments
HCA (Heavy Compression Attention): merges every 128 tokens into a topic-level index, enables fast global scanning
Think of it as a reference librarian: scan the index cards first (HCA), identify candidates, then pull only the relevant shelves (CSA). The same logic behind effective exam prep — chapter summaries first, targeted deep reading second.
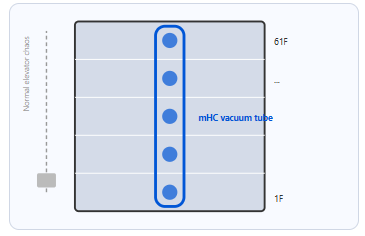
Manifold-Constrained Hyperconnection (mHC): Keeping Signals Alive at 61 Layers
61 layers deep creates a real engineering problem: gradient signals degrade as they propagate backward through the network. Deep networks become unstable to train.
mHC establishes constrained direct connections between layers, preserving the geometric structure of gradient signals in transit. The practical result: stable training at 1.6 trillion parameters. That’s not a footnote — it’s the thing that makes the rest of this possible.
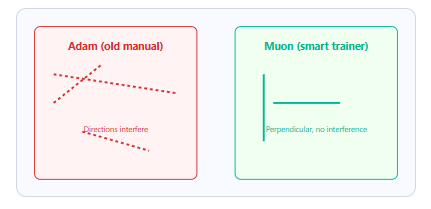
Muon Optimizer: Why Adam Was the Wrong Coach
The industry default is Adam. Its limitation: parameters are coupled — adjust one, and the update direction of adjacent parameters shifts. Training oscillates.
Muon enforces orthogonality between parameter updates. Each parameter moves in its own direction without interfering with others. Coordinating 1.6 trillion parameters simultaneously, each converging independently.
The Huawei Ascend Question
This is the one everyone’s actually asking about. Here’s what the evidence shows.
Pre-training: The paper doesn’t state this explicitly, but it almost certainly ran on NVIDIA GPUs. The CUDA ecosystem’s maturity is still irreplaceable for ultra-large-scale training. There’s no alternative path at this scale yet.
Inference: This is where the verified numbers exist. DeepSeek’s paper documents side-by-side validation on both NVIDIA GPU and Huawei Ascend NPU platforms for their MegaMoE fine-grained expert parallelism scheme. The results:
Inference speed: 1.5–1.7× improvement on both platforms
Latency-sensitive scenarios: up to 1.96×
Performance parity between platforms: confirmed
Specific Ascend 950 benchmark for V4-Pro: 20ms response latency at 8K input, 4,700 tokens/second single-card throughput.
This is the first time a domestic AI chip has received this level of production-grade validation in a large model inference context. Not a demo. Not a lab benchmark. Deployable performance data.
The honest assessment: The pre-training wall still belongs to NVIDIA. On inference, an alternative path now credibly exists.

Real-World Benchmarks Over Synthetic Ones
DeepSeek did something worth acknowledging in this report: they published real-task comparisons against competitors, not just leaderboard scores.
The numbers worth retaining:
Chinese writing: Higher win rate versus Gemini 2.5 Pro; loses to Claude Opus 4.5 on complex multi-turn writing.
White-collar task evaluation (internal benchmark — report drafting, data analysis, email composition, meeting notes): V4-Pro Max outperforms Opus 4.6, rated as one of the most practically useful capability dimensions.
Coding: Blind evaluation by 85 professional developers — 52% rated V4-Pro as viable as a primary coding model, UX better than Claude Sonnet 4.5, code quality approaching Opus 4.6.
This framing is more honest than MMLU scores. It also tells you exactly where the gaps are.
Pricing: The Actual Market Move
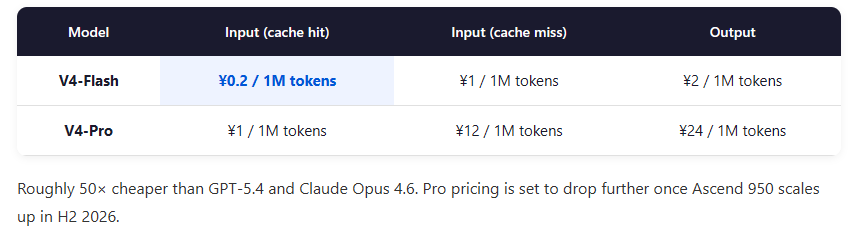
V4-Flash output: ¥2 / million tokens (~$0.28)
V4-Pro output: ¥24 / million tokens (~$3.30) 75% discount until May 5th
GPT-5.4 / Claude Opus 4.6: roughly 50× more expensive
With Ascend 950 reaching volume production in H2, the Pro price has further room to drop.
This isn’t competition. It’s price-layer restructuring.
Agent Capability: This Model Is Actually Doing Work
V4 was trained on millions of real agent interaction trajectories in its post-training phase. What that means in practice:
Give V4-Pro: “Convert all PDFs in my folder to text, extract every paragraph mentioning ‘2025 budget’, format as Excel, send to my email.”
It calls a PDF parser → runs keyword extraction → generates the spreadsheet → connects to mail service. End to end, unassisted. This isn’t a marketing demo — it’s the documented boundary of what the training data was designed to produce.
Real Test: Can DeepSeek V4 Take Over Your Claude Workflow?
Technical reports only tell you so much. I tested V4 directly inside my own Claude Code Skill pipeline to see whether it’s a workable substitute.
Setup: Switched to DeepSeek V4 via CC Switch inside Claude Code, then ran the same Skill instructions I normally use with Claude Sonnet.
Task: Take a local PDF (deepseek_v4.pdf), generate an HTML analysis report, following the frontend-design Skill’s full output spec.
The short answer: functional, with real caveats.
V4-Pro correctly parses format constraints, design requirements, and output specs when they’re written out explicitly. If your Skill instructions are precise — specific about output format, visual style, tech stack — it largely delivers.
Where the gap shows: implicit conventions. The frontend-design Skill has a set of “this goes without saying for any web component” assumptions that Claude Sonnet respects automatically. V4-Pro needs those assumptions made explicit. It’s not a blocker, but it’s a cost.
What this means for developers: If your workflow depends on finely-tuned Skills with implicit context, V4-Pro is a migration with real friction — not a zero-config swap. If your tasks are well-scoped and your instructions are explicit, the 50× price difference is worth a serious evaluation.
Tools like SuperPower (which handles complex agentic workflows including cross-border e-commerce ERP) have also completed V4 integration testing with aligned results. For agent tasks with well-defined business logic, the connective infrastructure is production-ready.
The conclusion is practical: V4 is a viable domestic alternative for structured, explicit workflows. It’s not yet a seamless replacement for Claude in contexts where the model is expected to infer from convention.
The Part That Deserves Credit
DeepSeek’s announcement explicitly acknowledges that its chain-of-thought reasoning still trails the strongest closed-source models.
In this industry, saying “we’re not there yet” takes a kind of deliberate restraint. That same restraint makes every other number in the report more credible.
Not seduced by praise. Not deterred by slander.
Based on the engineering, they mean it.
If this is useful, subscribe to ZeroFuture Tech — tracking the intersection of AI tooling and supply chain digitalization.